스키마?
RDB에서 스키마란 정보를 구성하고 데이터가 저장될때에 약속을 만들어 주는것이라고 생각합니다. RDB에서는 스키마를 정의한 형태로 데이터를 입력해야하고 사전에 정의된 스키마의 내용과 다른 데이터를 추가하려고 시도하면 작업은 실패합니다.
카프카에서 스키마가 없을때의 예를 들어 보자면 한명만 카프카를 사용한다면 별 다른 이슈가 없겠지만 수많은 사용자가 카프카를 사용하고 수많은 사용자가 수많은 토픽을 사용합니다. 그리고 토픽마다 각기 다른 애플리케이션에 접근하기 때문에 하나의 데이터라도 사전에 정의되지 않은 토픽으로 데이터가 이전돼면 큰 문제가 생길 것입니다.
카프카는 대부분 브로드캐스트 방식으로 데이터를 전송하기 때문에 프로듀서를 일방적으로 신뢰 할 수 밖에 없는 방식입니다. 따라서 프로듀서 관리자는 카프카 토픽의 데이터를 컨슘하는 관리자에게 반드시 데이터 구조를 설명해야한다.
데이터를 컨슘하는 여러 부서에게 그 데이터에 대한 정확한 의미를 알려주는 역할을 하는것이 바로 스키마입니다.
일이 많지만 스키마를 미리 정의하면 데이터 트러블슈팅 감소, 용이한 데이터 포맷 확인, 데이터 스키마 관련 커뮤니케이션 감소 등 얻을 수 있는 이점들이 많기 때문에 카프카에서 스키마 사용은 권장사항에 속합니다.
스키마 레지스트리
카프카에서 스키마를 활용하는 방법은 스키마 레지스트리라는 별도의 애플리케이션을 이용하는것입니다. 오픈소스 라이선스가 아니라 비상업적인 용도가아니면 비용이 지불됩니다.
가장 대표적인 포맷은 에이브로입니다.
에이브로?
에이브로는 시스템, 프로그래밍 언어, 프로세싱 프레임워크 사이에서 데이터 교환을 도와주는 오픈소스 직렬화 시스템입니다. 아파치 하둡프로젝트에서 처음 시작됐습니다. JSON, 프로토콜 버퍼 포맷도 지원합니다.
JSON과 달리 에이브로는 데이터 필드마다 데이터 타입을 정의할 수 있고, doc을 이용해 각 필드의 의미를 데이터를 사용하고자 하는 사용자들에게 정확하게 전달할 수 있습니다.
{"namespace": "student.avro", 1
"type":"record", 2
"doc": "This is an example of Avro.", 3
"name": "Student", 4
"fields": [ 5
{"name": "name", "type" : "string", "doc" : "Name of the student"},"l
{"name": "class", "type": "Int", "doc" : "Class of the student"} ]6
- namespace:이름을 식별하는 문자열
- type:에이브로는 record, enums, arrays, maps 등을 지원하며,여기서는 record 타입으로 정의
- doc:사용자들에게 이 스키마 정의 대한 설명 제공(주석)
- name:레코드의 이름을 나타내는 문자열로서,필숫값임
- fields:JSON 배열로서,필드들의 리스트를 뜻함
- name:필드의 이름
• type:boolean, Int, long, string 등의 데이터 타입 정의 • doc:사용자들에게 해당 필드의 의미 설명(주석)
스키마 레지스트리 옵션 설정
listeners=http://0 .0.0.0:8081 1
kafkastore.bootstrap.servers=PLAINTEXT://카프카호스트네임 2
kafkastore.toplc=_schemas 3
schema•compatibility•level=full 4
1 listeners:스키마 레지스트리에서 사용할 TCP 포트를 8081 포트로 지정합니다.
2 kafkastore.bootstrap.servers:스키마의 버전 히스토리 및 관련 데이터를 저장할 카프카 주소를
입력합니다.
3 kafkastore.topic:스키마의 버전 히스토리 및 관련 데이터 저장 토픽의 이름을 _schemas로 지정
합니다.
4 schema. com patibility. level: 스키마 호환성 레벨을 fu ll로 설정합니다.
브로커의 _schemas 토픽이 스키마 레지스트리의 저장소로 활용 되며 모든 스키마의 제목,버전,id등이 저장됩니다. 순서를 지키기 위해서 _schemas 토픽의 파티션 수는 항상 1 입니다.
스키마 레지스트리를 실행후
sudo vi /etc/systemd/system/schema-reglstry.service
로 들어가서 시스템 설정을 해줍니다,.
//카프카 시스템 설정
[Unit]
Descrlptlon=schema registry After=network•target
[Service]
Type=simple
ExecStart=/usr/local/confluent/bln/schefna-registry-start /usr/local/confluent/etc/ schema-registry/schema-reglstry.properties
Restart=always
[Install] WantedBy=multl-user•target
후 데몬 제실행
스키마 레지스트리 api 리스트
GET /schemas : 전체 스키마리스트 조회
GET /schemas/ids/id : 스키마 아이디로 조회
GET /schemas/lds/id//versions : 스키마 id 버전
GET /subjects : subject리스트
GET /subjects/서브젝트이름/versions : 특정 서브젝트 버전 리스트조회
GET /config : 전역으로설정된 호환성 레벨 조회
GET /config/서브젝트이름 : 서브젝트에 설정된 호환성 조회
DELETE/subjects/서브젝트이름 :특정 서브젝트 전체삭제
DELETE/subjects/서브젝트이름/versions/버전 : 특정서브젝트에서 특정 버전만 삭제
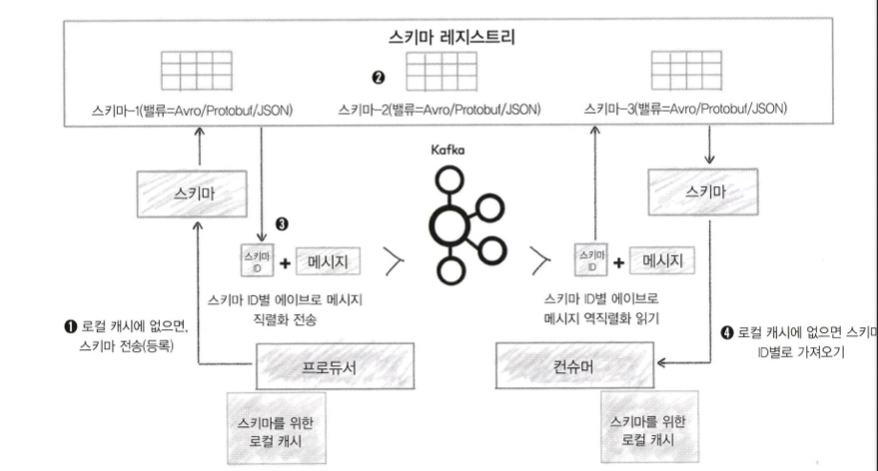
스키마 레지스트리와 클라이언트 동작(출처: https://docs.confluent.io/platform/current/schema-registry/index.html)
- 에이브로 프로듀서는 컨플루언트에서 제공하는 새로운 직렬화를 사용해 스키마 레지스트리의 스키마가 유효한지 여부를 확인합니다. 만약 스키마가 확인되지 않으면, 에이브로 프로듀서는 스키마를 등록하고 캐시한다.
- 스키마가 업데이트됐는지 체크 각 스키마에대해 고유 id 할당.
- 프로듀서가 스키마 레지스트리로 부터 받은 스키마id를 참고해서 메시지를 카프카로 전송. 이때 스키마 전체내용이 아닌 메시지와 스키마 id만 보냅니다.
- 에이브로 컨슈머는 스키마id 로 새로운 역직렬화를 사용해서 카프카의 토픽에 저장된 메시지를 읽습니다. 컨슈머가 스키마 id 를 가지고 있지 않다면 스키마 레지스트리로 부터 가져옵니다.
스키마 레지스트리 호환성
스키마 레지스츠리에서는 하나의 서브젝트에 대한 버전 ㅂ정보별로 진화하는 각 스키마를 관리해줍니다. 또한 스키마가 진화함에 따라 호환성 레벨을 검사해야하는데, BACKWARD, FORWARD, FULL 등의 호환성 레벨을 제공합니다.
BACKWARD 호환성
BACKWAD 호환성이란 진화된 스키마를 적용한 컨슈머가 진화 전의 스키마가 적용된 프로듀서가 보낸 메시지를 읽을 수 있도록 허용하는 호환성을 말합니다.
FORWARD 호환성
진화된 스키마가 적용된 프로듀서가 보낸 메시지를 진화 전의 스키마가 적용된 컨슈머가 읽을 수 있게 하는 호환성을 말합니다.
FULL 호환성
위 두가지 호환성을 모두 지원합니다.
'kafka' 카테고리의 다른 글
| 카프카 커넥트 정리 (1) | 2023.10.19 |
|---|---|
| 카프카 버전업그레이드 (0) | 2023.10.19 |
| 카프카 운영,모니터링 (1) | 2023.10.19 |
| 카프카 / 컨슈머의 내부동작 원리 (0) | 2023.10.19 |
| 프로듀서 내부동작원리 (1) | 2023.10.19 |