스프링 서버는 put을 사용해서 update를 할 때 자바스크립트를 이용해야 한다 form 태그에는 post와 get밖에 없기 때문입니다.
그럼 put을 사용할 때 두 가지 방법이 있다.
1.form에 있는 데이터를 한꺼번에 들고 오는 방법.
2.


onsubmit 속성은 submit버튼이 ture면 함수가 실행되고 false면 실행되지 않는다. onsubmit을 사용했을 때 장점은 action을 하기 전에 유효성 체크를 같이 하는 용도로 나왔었다. gkwlaks 지금은 put 하기 위해 사용된다.
근데 submit버튼을 누르면 페이지가 새로고침이 되기 때문에 그것을 막아줘야 한다. event.preventDefault()
자바스크립트는 어떤 이벤트가 됐던 모든 이벤트가 발생하면 현제 이벤트의 모든 정보를 매개변수로 넣어준다. event
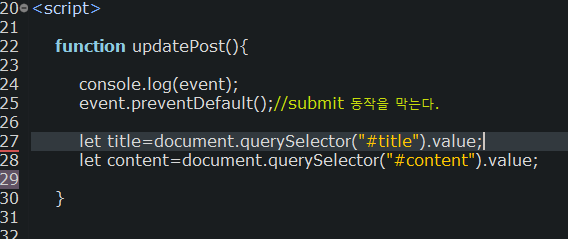

querySelector는 해당 아이디 밑 클래스에 속성 값을 찾아준다(html파싱). 위 코드에서는 태그의 id값을 넣었다. querySeletor는 id는 "#아이디 값"이고 class의 name을 찾을 때는 ". 아이디 값"을 사용한다.
querySelectorAll은 여러 건의 속성 값을 찾아주는데 이 함수는 크롤링할 때 정말 많이 사용하는 함수다.
Put 기능 구현

querySelecoter를 사용하면 해당 아이디나 클래스를 찾을 수 있는데 title과 content를 찾기 위해서 사용해줬다
action은 기능과 method는 자바스크립트에서 막아 놨기 때문에 필요 없는 코드라 지웠다.

어떤 데이터를 가져올지 선택하고. json으로 바꾼 뒤에 fetch함수를 통해서 응답해줄 데이터를 타입에 맞게 설정해 준다.

찾고 싶은 정보의 클래스나 아이디 값을 찾은 뒤에

querySelecoter를 사용하면 해당 아이디나 혹은의 엘레멘트를 다 찾아준다.
그럼 이제 이 방법을 통해서 웹브라우저를 통해 데이터를 응답받으면 ByteStream을 통해서 받을 수 있는데 이때 버퍼를 사용해서 받는다. 그럼 이 문자열로 받은 html 코드들을 파싱을 해서 데이터를 수집하는 것이 크롤링의 한 방법이라고 할 수 있다.
이때 파싱을 해주는 라이브러리가 있다.
JSoup라는 라이브러리이다.

자바스크립트에서 파일이 아닌 데이터를 넘겼기 때문에 @ResponseBody를 사용해서 데이터를 리턴 받도록 하고 post매개변수 또한 오브젝트가 아닌 데이터로(버퍼드 리더) 받을 수 있도록 @RequestBody를 사용했다.

삭제하기


삭제하기는 간단하니 자세한 설명은 생략
위와 같이 update와 delet를 짜 보면 post와 get과 요청 방식이 달라 지기 때문에 가독성도 떨어지고 요청도 복잡해 지기 때문에 여러 가지 힘든 사항이 발생할 수 있다.
그렇기 때문에 정석은 post요청과 get요청 또한 update와 delet처럼 자바스크립트로 요청을 처리하고 응답을 하는 것이 국 룰이다
https://25gstory.tistory.com/73?category=0
자바스크립트 기본개념(기본 문법, 내장객체,이벤트 리스너,호이스팅,콜백, 비동기 프로그래밍)
자바스크립트의 기본적인 개념을 위해 세가지정도 포스팅을 할 것입니다. 1. 문법 2. 내장 객체 -최상위 내장 객체 window(java에서 Object 같은 개념) -history, location, document 3.fetch api(PUT, DELETE) -..
25gstory.tistory.com
post와 get요청을 자바스크립트를 하는 방법은 위 포스팅을 참고한 뒤 컨트롤러만 수정해 주면 가능해진다.
크롤링
찾고 싶은 정보의 클래스나 아이디 값을 찾은 뒤에
querySelecoter를 사용하면 해당 아이디나 혹은의 엘레멘트를 다 찾아준다.
그럼 이제 이 방법을 통해서 웹브라우저를 통해 데이터를 응답받으면 ByteStream을 통해서 받을 수 있는데 이때 버퍼를 사용해서 받는다. 그럼 이 문자열로 받은 html 코드들을 파싱을 해서 데이터를 수집하는 것이 크롤링의 한 방법이라고 할 수 있다.
이때 파싱을 해주는 라이브러리가 있다.
JSoup라는 라이브러리이다.

JSop도 querySelecoter랑 같이 크롤링할 때 많이 사용되는 라이브러리이다.
'Springboot' 카테고리의 다른 글
| Exception처리(기본개념) (0) | 2021.07.20 |
|---|---|
| Spring boot/JPA 로 블로그만들기. 코멘트 기능 구현(댓글) (3) | 2021.07.19 |
| Springboot사용해서 블로그 만들기 글쓰기기능(summernote에디터사용) 추가와 상세보기 페이지(삭제,수정) 회원정보 변경 (0) | 2021.07.07 |
| SDK사용해서 SMS서비스 만들기 (0) | 2021.07.06 |
| Spring boot/JPA 실습 블로그를 만들어보자!(회원가입 페이지 주소 API사용) (0) | 2021.07.05 |